[Originally posted in May 2013 – We’re finding this article content is as viable today as it was then, so we’re re-posting]
The “I” in Information Technology is incredibly broad, so why do we specifically focus on “spatial data” when approaching integrated data science problems? Why is it first in our data areas: Geospatial, Open, Big, IoT? We get this question a lot. Our reason for focusing on Geospatial is that it is multi-dimensional. It crosses many different ways of thinking, audiences of varying maturity, progressions, sciences, models, and times.
Analyzing the History of Information
From the perspective of time, and mostly following Moore’s Law, we know technology is developing far too quickly. The long-term applicability of Moore’s Law has been questioned recently (MIT declared Moore’s Law dead in 2016, then IBM noted it was alive again in 2017). However, this rapid doubling – 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024, 2048, 5096, 10k, 20k, and so forth– has seen a 10,000-fold increase in computing and storage capability in fewer than 20 years. 90% of that increase occurring in the last 10 years alone.
To show this progress in terms of the “I” in “IT”, we have put together a few views on this rapid curve shown below. The curve measures the progression from data to information to knowledge, and to wisdom (y) over time (x).
1 2 3 4
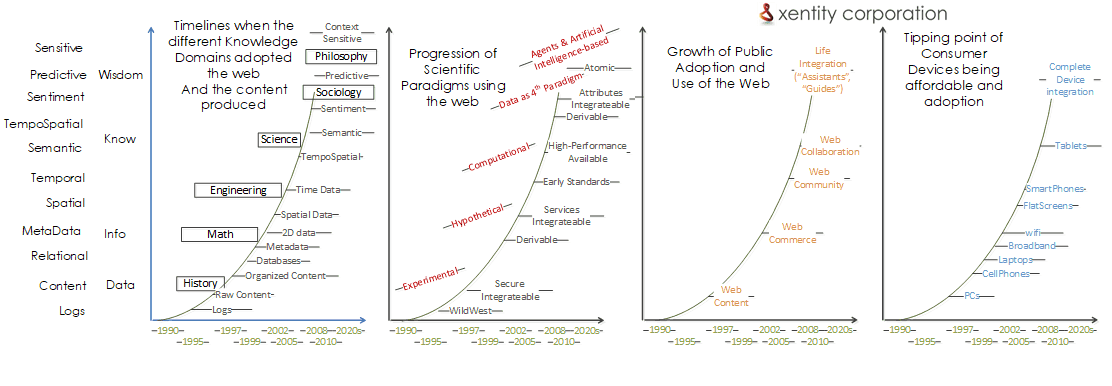
If we take only public web content, then data on the web is at the beginning of the curve. Early data products have had the longest time to mature, about 10-15 years. However, they can only improve as they mature further, reaching 25 years and beyond.
We have been in an information period since 2010s. However, the technological advance that coincided has us moving too quickly into the knowledge period. Think how dependent we are on the Internet today. Remember how often you were on the web in 1998 compared to 15 years later. Now with smartphones, the web fits right in your pocket now. Now, think how AI, IoT, and new interfaces will change everything in another 15 years.
Taking in the progression of this high-level concept, we have mapped out four different impacts (or progressions):
- Common knowledge domain progression
- Scientific capability progression
- Adoption progression
- Device progression
First Progression
Our first progression traces a timeline of web uptake by different knowledge domains. It begins with primarily using the internet to search historical records, then for computational math in the 90s. Now it has moved into hard science analytics, personalized signals, and models. We are now only a decade or so away from sentiment and sensitive capabilities, raising profoundly complex socio-ethical and philosophical discussions once only the realm of science fiction and computer science geek talk.
This means the 40 year reign of MIS / information systems over the computing world is practically over. Data-driven enterprises using analytics to support decisions have taken over in its place. It is now a race for organizations to rapidly move towards knowledge first.
This is why GIS has been shifting to geospatial data products and services over the last decade. Knowledge is taking the lead over records, business process, and compliance processing.
Second Progression


The second progression tracks the progress of scientific capabilities. Science used to be experimental, hypothetical, and conducted in laboratories. A generation ago it moved into computational models. Now those models are expected to be fed big, fast, spatial data from records, taxonomies, sensors, and shared research. This is not an information system; it is a web of atomic data. The fact that communities of end-users are demanding improved data flow, better supply chains, and advanced experiences to address these gaps and move beyond MIS models speaks volumes about how data qualities are severely lagging behind technology in investment. Again, this is due to technology requiring the same level of investment every two years to double production capabilities, whereas data is currently still linear and providing an analogous level of investment return.
Third Progression
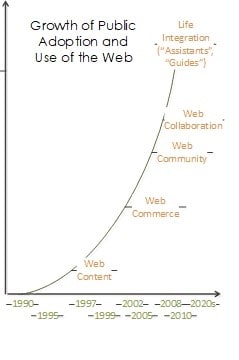
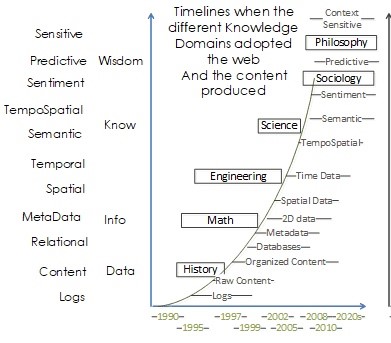
The third progression tracks public adoption of the web. What used to be squirreled away in government skunkworks or the proprietary research data moats of financial, energy, and marketing organizations is now in public collaboration environments. Jupyter notebooks are moving into event-driven architectures. As each capability is adopted, it demonstrates how much the leading industries have invested, much like the progress of human intelligence over the history of humankind. Originally, adoption was about moving content to digital, then secure, information-exchange commerce transactions. Next, communities formed online, overcoming geographic limitations. Finally, those communities found niche ways to collaborate together. This tracks with the offline progression from writing to payment to trade to industry over thousands of years, yet on a Moore’s Law scale of a few decades.
Fourth Progression
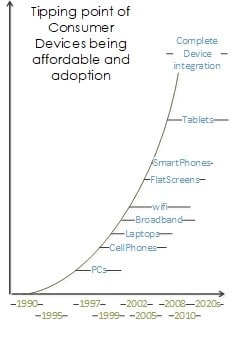
Finally, the fourth progression tracks the adoption of consumer devices, such as smartphones and laptops. At this point, computers have shrunk to the point where they are getting ever so close to data itself. From powerful phone and tablet computing, to process sensor and field collection with direct communication, to collaborative and service applications, to immensely flexible and scalable computing available to anyone with a credit card, to fat pipes bringing data to world-class computing (aka, the cloud). Data centers or desktops no longer confine the computer; nodes are truly everywhere.
What comes next? The next 10-15 years will be the decade of the interface, as physical barriers no longer confine form factor. We are only beginning to experiment with adjustments to reality – augmented reality, virtual reality, beacons, and online avatar MMORPG worlds. What these new interfaces will become, for now the creatives of the world are only teasing us – smart home, smart city, holographic interface, IoT lenses (glasses or embedded), even singularity?
Circling Back to Where We Began
If you look back to the beginning of this blog and agree that professional spatial mapping originated in the early 2000s, you will understand that spatially-tagging data has passed both these tipping points with the advent of smartphones, map apps, local scouts, augmented-reality directions, and multi-dimensional modeling integrating GIS and CAD with the web. As such, you can see the data science maturity stage that has the largest impact right now is the data we focus on: Geospatial.
Geospatial data is different. Prior to geospatial, data was non-dimension-based. It had many attributable and categorical facets, but it did not have to be stored in a mathematical or picture form with specific relation to the earth’s position. Spatial data – GIS, CAD, Lat/Longs, has to be stored in numerical fashion in order to calculate upon it. Furthermore, it has to be related to a grounding point. Geospatial is essentially storing vector maps or pixel maps.
So What?
When you begin to put that together for 10’s of millions of streams, you get a very large, complicated, spatially referenced hydrography dataset. It gets even more complicated when you overlay that with 15-minute time-based data, such as water attributes (flow, height, temperature, quality, changes, etc.). It becomes even more complicated when you combine that data with other dimensions, such as earth elevations. Then you need to relate it across the disparate domains of science, speaking different languages to calculate how fast water may flow through a certain containment down a slope after a riverbank or levy collapses.
What we see with all of this information, is that geospatial data is the next logical progression in data complexity. As such, not only are we passionate about geospatial data (among many other kinds of data), we wish to devote our efforts to understanding it are keys to our success in the field of data science.
For more information on a particularly expansive subject, check out our next blog: “The Challenges of Perpetual Acceleration”.