In 2013, we published Why We Focus on Spatial Data Science, which outlined how the web matured across four predictable progressions: timeline, scientific capability, public ado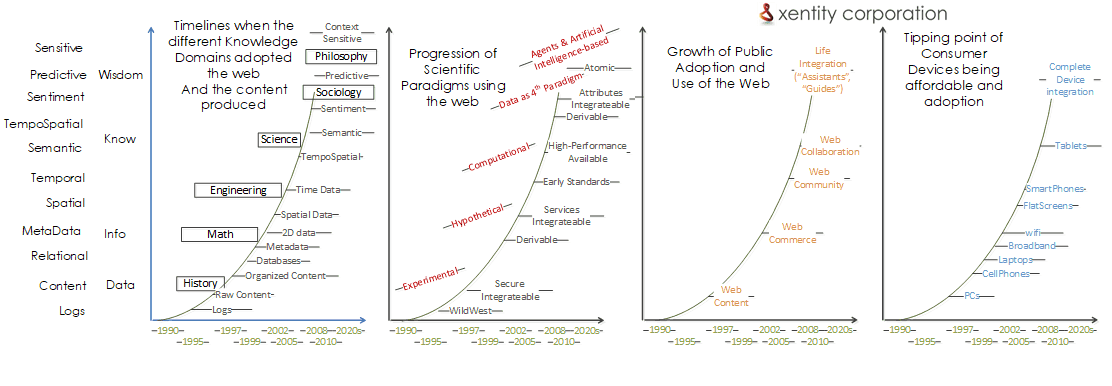 ption, and device proliferation. Those progressions helped leaders understand how foundational transformations take hold—and what data foundations they require AI.
ption, and device proliferation. Those progressions helped leaders understand how foundational transformations take hold—and what data foundations they require AI.
Today, an equally significant shift is underway with Artificial Intelligence (AI). The pace is faster, the stakes are higher, and the impacts span every domain of human knowledge and infrastructure. To understand where we are and where we’re going, we revisit the same four-progression framework and update it for the era of LLMs, multimodal models, AI agents, robotics, and emerging general reasoning. This article draws from our internal GenAI research, public sources, our Xentity blog AI Ain’t Taking Over the World… Yet (https://www.xentity.com/ai-aint-taking-over-the-world-yet-so-they-want-you-to-think/), and the OGC D-123 Engineering Report’s “Technology Components Needed to Support GenAI” section—which provides one of the clearest snapshots of the state of AI infrastructure as of 2024.


These progressions also clarify what data, governance, and engineering scaffolding must exist. Each mirrors the structure of the 2013 article but is updated for LLMs, agents, RAG, multimodal models, and the augmentation technologies required for GenAI maturity (RAG, Agents, GAN, NLP) as summarized in the OGC D-123 GenAI Engineering Report’s “Technology Components Needed to Support Gen AI” section (particularly as applied to wildland fire management).
Progression 1: From History Machines to Philosophy Engines
AI Across the Major Knowledge Domains: (History → Math → Science → Engineering → Sociology → Philosophy)
We can think of AI’s trajectory as climbing a ladder of human knowledge domains. Classical models identify History, Math, Science, and Philosophy as the four pillars. In the modern world, Engineering and Sociology sit between and around these: designing what works (engineering) and understanding how groups behave (sociology). Each domain requires deeper abstraction and more contextual judgment.
Today’s AI—LLMs, chat models, and basic RAG systems—live primarily in the History domain. They reorganize and synthesize what humanity has already written. As we add math tools, symbolic reasoning, and domain-specific copilots, AI begins to step into Math: solvers, tutors, and code generation. Moving into Science and Engineering requires models that can work with simulations, constraints, and cause–effect reasoning. Sociology and Philosophy then demand the ability to reason about values, norms, institutions, and “what should be done,” not just “what is.”
The “AI Progress Through Knowledge Domains” chart shows this progression over roughly a decade as a logarithmic curve—slow at the bottom, steeper as we climb. Early years are dominated by LLM chat & search and domain RAG assistants. As we move forward, we see code copilots, math solvers and tutors, and science simulation copilots appear at scale. Deeper into the curve we start to see AI-aided engineering design, policy modeling assistants, social behavior modeling, and eventually ethics guidance agents and personal reflection assistants as mainstream tools, not just prototypes.
This progression matches what researchers and practitioners are observing: “Great AI is moving from content to math” (see the talk at https://www.youtube.com/watch?v=y8NtMZ7VGmU). That shift is visible in Google DeepMind’s recent International Math Olympiad performance (https://arstechnica.com/ai/2025/07/google-deepmind-earns-gold-in-international-math-olympiad-with-new-gemini-ai/), where AI systems are no longer just reciting history but solving competition-grade math. Once AI is comfortable in math and simulation, it becomes far easier to extend it into science and engineering domains.
Progression 2: The Five Modalities of Science — From Data to Discovery
Experimental → Hypothetical → Computational → Data-Intensive → Agentic/AI Science
In our 2013 piece, we looked at how web capabilities supported science. Here, we extend that thinking to AI and the modalities of science itself. Building on Jim Gray’s “Fourth Paradigm” work at Microsoft Research (“data-intensive science”) and current AI research, we can see five modalities where AI plays a role:
Experimental Science — designing, running, and analyzing experiments
Hypothetical/Theoretical Science — generating and refining theories, models, and conceptual frameworks
Computational Science — simulating complex systems and optimizing outcomes
Data-Intensive Science — extracting patterns, correlations, and predictions from large datasets
Agentic/AI Science — agents autonomously exploring hypotheses, experiments, and literature with human-in-the-loop oversight
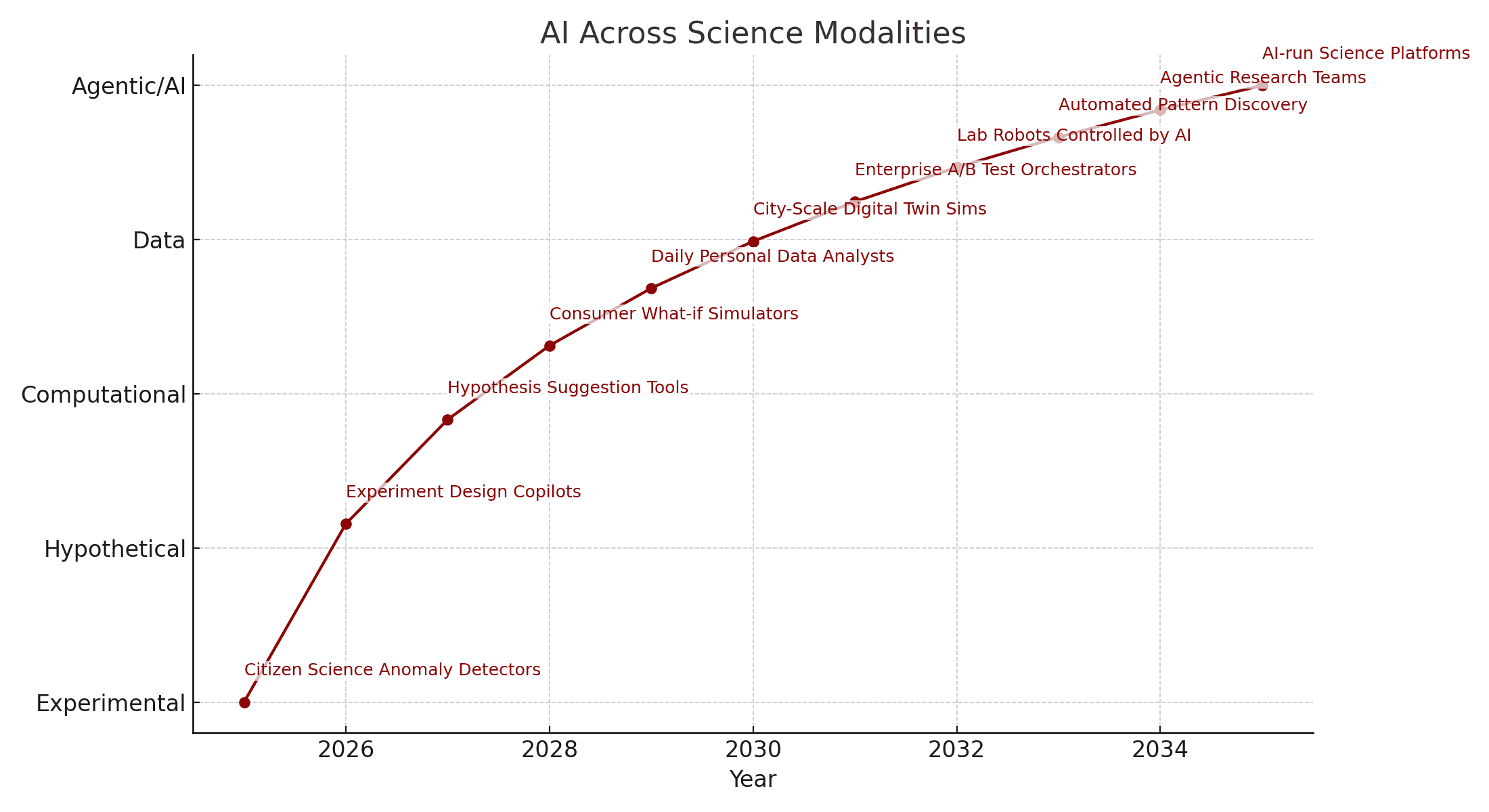
Today’s AI is strongest in Data-Intensive and Computational science—classifying satellite imagery, building digital twins for wildfire or urban systems, forecasting demand, and running global-scale simulations. But it is rapidly moving up the stack. Large models are now used as hypothesis suggestion engines (scanning literature, proposing mechanisms), experiment design copilots (suggesting what to test next in labs), and orchestrators of lab robots in experimental setups. Articles in Nature and Science have started to explore whether AI should be considered a co-author in scientific research, and MIT Technology Review has chronicled how AI is reinventing scientific simulation.
The “AI Across Science Modalities” chart captures this shift, again on a logarithmic curve. Early points include citizen science anomaly detectors and experiment design copilots, followed by consumer what-if simulators (“If I change diet, investments, routes, what happens?”) and daily personal data analysts. As we move into the future portion of the curve, we see city-scale digital twin simulations, enterprise A/B test orchestrators, lab robots controlled by AI, and finally agentic research teams and AI-run science platforms (always with human oversight).
This is where ANI → AGI → ASI becomes a useful lens, as discussed in our own article “AI Ain’t Taking Over the World… Yet”. ANI maps to today’s data-intensive and computational AI: highly capable in narrow contexts. AGI would be able to form hypotheses, design experiments, and reason across domains—operating at the hypothetical and experimental levels. ASI, if it emerges, would correspond to truly agentic science ecosystems that can discover and test ideas at a scale and speed far beyond any human organization—raising serious governance and alignment questions.
The OGC D-123 GenAI Engineering Report’s “Technology Components Needed to Support Gen AI” section reinforces that this is not magic; it’s infrastructure. Agentic/AI Science requires provenance-rich data, multimodal grounding, RAG, GAN-based augmentation, and orchestrated AI agents working inside frameworks like the NIST AI Risk Management Framework and other responsible AI guardrails.
Progression 3: The 4 C’s of AI Adoption — Content, Commerce, Community, Collaboration
In the 2013 article, one of the most understandable frameworks was the 4 C’s: Content, Commerce, Community, Collaboration. The public doesn’t adopt technology directly as “protocols” or “APIs”—they adopt it through what they can do with it. The same applies to AI.
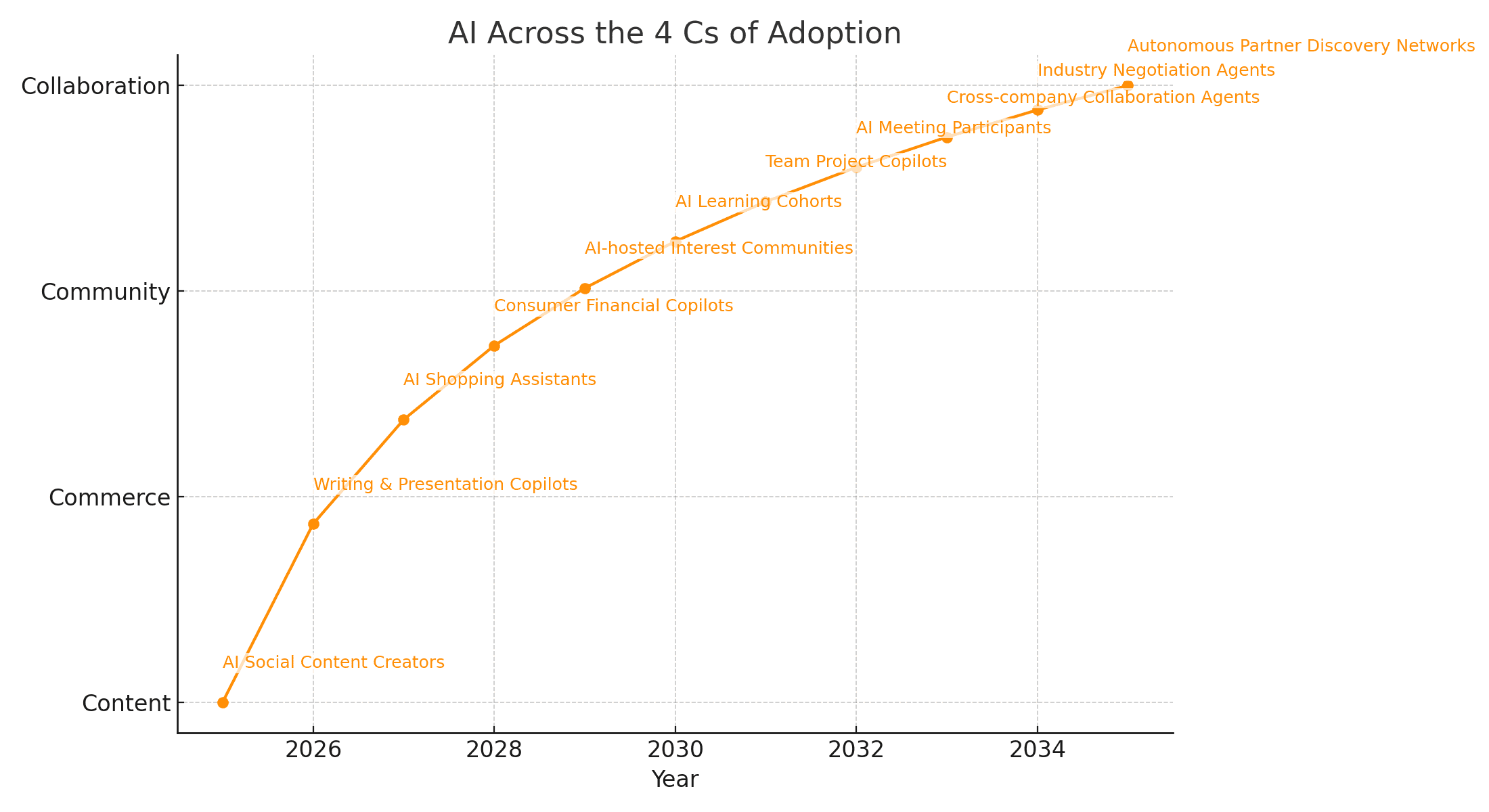
Right now, the world is deep into the Content phase. Generative AI for writing, images, audio, video, code, and presentations has crossed the tipping point, with tools like ChatGPT, Gemini, Claude, GitHub Copilot, Midjourney, and countless others. The “AI Across the 4 C’s of Adoption” chart shows how this growth is moving outward and upward. Early points on the curve mark AI social content creators and writing/presentation copilots—the tools already embedded into office suites, browsers, and creative workflows.
The next phase is Commerce: AI shopping assistants, personalized product discovery, consumer financial copilots, and embedded risk models in banking and insurance. McKinsey’s Economic Potential of Generative AI report, Gartner’s AI Hype Cycles, and the Stanford AI Index all show strong investment and ROI patterns here. AI is increasingly present at the point of transaction—helping people choose, price, and secure what they buy and sell (https://www.mckinsey.com, https://www.gartner.com, https://aiindex.stanford.edu).
Beyond that, Community emerges when AI becomes part of who we learn and socialize with. The chart’s next points include AI-hosted interest communities and AI-facilitated learning cohorts, where AI tutors coordinate group progress, community moderation, or fandom experiences. Finally, we reach Collaboration, with team project copilots, AI meeting participants and summarizers, cross-company collaboration agents, industry negotiation agents, and autonomous partner-discovery networks.
As we described in the spatial data science context, this reflects a combination of Malcolm Gladwell’s “tipping point” and Metcalfe’s Law: when AI tools move from individual productivity to group coordination and inter-organizational workflows, network effects kick in. AI no longer just generates content; it becomes part of how teams, industries, and ecosystems coordinate work.
Progression 4: Physical Instantiation — Where AI Leaves the Cloud and Enters the World
The fourth progression in the 2013 article focused on device adoption—smartphones, tablets, and sensors. For AI, this progression is broader and more layered, because AI is not just an app on a device; it becomes part of the entire physical stack.
We can think of this progression in six layers, as shown in the “AI Physical Instantiation Curve”:
Devices — AI-enabled phones, laptops, and AR glasses running on-device LLMs and vision
Robots & Drones — home service robots, warehouse robots, agricultural machinery, inspection and delivery drones
Vehicles — autonomous ride-hailing fleets, highway platooning, farm and construction vehicles
Networks — smart traffic lights, routing and logistics networks, emergency response routing
Systems — energy grid optimization, factory and port orchestration, intermodal logistics control
Human Integration — brain-computer interfaces (e.g., Neuralink: https://neuralink.com), augmented cognition overlays, and other Human+AI boundary blurring
The chart shows a decade of logarithmic growth up this stack. In the near term, we see AI phones & laptops and on-device AR/vision become ubiquitous. Then home service robots, industrial robotic arms, and delivery/inspection drones become common in homes and businesses—mirroring the pattern we’ve seen with firms like Boston Dynamics (https://www.bostondynamics.com) and in IEEE Spectrum’s coverage of AI-driven robotics (https://spectrum.ieee.org).
As we progress, autonomous fleets, farm/construction machinery, and smart traffic AI start to define entire transportation systems. Grid optimization AI and factory/port AI then tie into broader system-of-systems coordination. The far horizon includes brain-computer interfaces and cognitive extensions that echo Ray Kurzweil’s predictions in The Singularity Is Near (https://en.wikipedia.org/wiki/The_Singularity_Is_Near). Tesla’s Autopilot/FSD efforts (https://www.tesla.com/autopilot) and emerging work on “AI-defined factories” show early examples of how AI will increasingly govern how physical infrastructure behaves.
Conclusion: AI Progress Depends on Data Progress
Across all four progressions—knowledge, science, adoption, and physical instantiation—one reality stands out:
AI progress is limited far more by data quality, structure, lineage, and availability than by model architecture.
The OGC D-123 GenAI Engineering Report emphasizes that the next decade of AI expansion requires:
High-quality, multimodal data (text, imagery, spatial, sensor, graph, time-series)
Automated data integration pipelines (ETL → embeddings → RAG → agentic workflows)
Data provenance and micro-citation metadata to support trust and auditability
Bias controls, governance, and validation loops (aligned with NIST’s AI Risk Management Framework: https://www.nist.gov/itl/ai-risk-management-framework)
Trusted knowledge graph infrastructure to organize meaning and relationships
Federated, verifiable, zero-trust architectures for responsible, scalable deployment
These findings are echoed across major players: AWS’s guidance on building responsible AI systems, Google DeepMind’s work on frontier AI safety (https://deepmind.google), and numerous national and international AI policy efforts.
At Xentity, this is exactly where we focus:
Designing knowledge graphs, metadata models, and ontologies
Building data automation and quality pipelines that feed AI
Architecting multimodal RAG and agentic systems
Integrating spatial, temporal, and unstructured data
Engineering enterprise AI ecosystems that are explainable, governable, and resilient
These four progressions show how AI will move from history machines to philosophy engines, from simple predictors to agentic scientific collaborators, from isolated content tools to collaboration partners, and from cloud software to embedded infrastructure.
Our job is to ensure the data and governance foundations are ready—so AI can move from promise to practice responsibly.
Additional Context on the Evolution of AI
Early AI (e.g. Lisp and Scheme based):
- Symbolic AI: Early AI was primarily based on symbolic reasoning. This approach involved manually encoding knowledge and logic into the system. The AI would then use this knowledge to reason and make decisions.
- Expert Systems: These were computer systems that emulated the decision-making abilities of a human expert. They were rule-based systems that used a “knowledge base” of facts and heuristics to solve specific problems within a certain domain.
- General-Purpose Languages: Lisp and Scheme were favored for AI development due to their flexibility, symbolic processing capabilities, and recursive nature and placed nodes through tree traversing to capture related patterns.
- Limitations: These systems were limited by the knowledge encoded into them. They couldn’t learn from new data or adapt to changing environments without manual intervention.
Machine Learning (ML):
- Data-Driven: Unlike symbolic AI, ML algorithms learn patterns directly from data. This shift marked a move from handcrafted rules to models that could generalize from examples.
- Broad Applications: ML can be applied to a wide range of tasks, from image recognition to predicting stock prices.
- Requires Data: The effectiveness of ML models is often directly tied to the quantity and quality of the data they’re trained on.
- Algorithms: Techniques like decision trees, support vector machines, and clustering became popular.
Deep Learning (DL):
- Neural Networks: DL involves neural networks with many layers (hence “deep”). These models can learn complex patterns and representations from data.
- Breakthroughs in Vision and Language: DL led to significant advancements in image recognition, natural language processing, and other areas.
- Requires Large Datasets and Computing Power: Training deep neural networks requires vast amounts of data and computational resources.
- Transfer Learning: Pre-trained models can be fine-tuned on smaller datasets, making DL more accessible.
Large Language Models (LLM) used in GPT:
- LLM Explanation: LLMs explained without too many technical references in this jargon-free explanation of how AI large language models work
- Natural Language Understanding: LLMs have shown remarkable capabilities in understanding and generating human-like text.
- Few-Shot Learning: Models like GPT-4 can perform tasks with very few examples, showcasing their generalization capabilities.
- Broad Applications: From chatbots to content generation to code completion, LLMs have a wide range of applications.
- Limitations: While powerful, LLMs can sometimes produce incorrect or nonsensical outputs. They also require significant computational resources to train.
Overall Evolution:
- The journey from early AI to LLMs represents a move from manual rule-based systems to data-driven models that can learn and adapt.
- The focus has shifted from domain-specific solutions (expert systems) to general-purpose models (like GPT-4) that can tackle a wide range of tasks.
- The computational requirements have grown significantly, with modern models requiring specialized hardware and vast datasets.
- Ethical and societal implications have become more pronounced, especially with the widespread deployment of ML, DL, and LLMs.
In essence, while the goals of AI—to create machines that can simulate human intelligence—have remained consistent, the methods and tools have evolved dramatically over the decades.